

Start your free trial
Verify all code. Find and fix issues faster with SonarQube.
Get startedTL;DR overview
- Static code analysis is the automated examination of source code without executing it, using techniques such as abstract syntax tree (AST) parsing and predefined rule sets to detect bugs, security vulnerabilities, and style inconsistencies early in the development cycle.
- Modern static analyzers have evolved from basic 1970s lint tools to sophisticated engines capable of scanning entire codebases against continuously updated vulnerability knowledge bases, identifying issues that even experienced developers might miss.
- Benefits include faster detection of security flaws, reduced testing and debugging costs, enforced coding standards, and integration into CI/CD pipelines for continuous quality enforcement on every code change.
- Sonar's static analysis tools provide immediate feedback in the IDE and automated scanning in CI/CD workflows, helping teams build consistent, secure, and maintainable software at scale.
Have you ever spent hours debugging code only to find the issue stemmed from a basic coding error?
You’re not alone.
Static code analysis is a powerful tool that can catch these issues before you notice them. It scans your code and looks for issues like syntax errors, logic flaws, and security vulnerabilities before they cause real problems.
This step-by-step guide introduces static code analysis and explains its usefulness. You’ll also walk through how to choose and configure an analyzer for your code.
Finally, you’ll explore how Sonar, a leading static code analyzer, can help you craft cleaner, more reliable code.
What Is Static Code Analysis?
A static code analysis tool analyzes code without executing it and identifies potential bugs, security vulnerabilities, and style issues. It automatically finds issues in code early in the development process, saving precious time later when testing and merging code.
The first commercial static analyzer, Lint, was released in the 1970s.
Lint caught potential patterns in code that might cause it to function unexpectedly.
The errors returned were similar to the compiler warnings you see today.
However, while Lint made catching potential bugs easier for developers, it also produced a lot of false positives (also known as noise).
In the end, developers spent so much time reviewing false positives that the tool saved little time.
In the late 1990s, new code analyzers were released that scanned and compared an entire codebase with a knowledge base of potential issues and security vulnerabilities.
Teams could update the knowledge base with any new known issues or security vulnerabilities, enabling the analyzer to detect those new issues.
Newer tools have evolved further to analyze code by first breaking source code down into an abstract syntax tree (AST).
An AST is a data structure that breaks down code, including variables, functions, and control structures, into smaller pieces and organizes these pieces into a tree-like structure that’s easier to understand and analyze.
Using an AST, static analyzers can focus on logic issues without worrying about programming language details.
These analyzers are often included in build pipelines and integrated into IDEs so developers can detect issues while writing code.
Today’s static code analyzers follow these fundamental principles:
- Static code analysis means that these analyzers don’t compile and execute the code to test it. Instead, they create ASTs and use those to find unused code or code that might give errors if specific inputs are provided.
- Predefined rules are stored in a knowledge base. These rules relate to coding standards, best practices, security vulnerabilities, and code complexity. The analyzer checks whether the code within the AST adheres to these rules. For example, an analyzer can look at how a variable is declared and accessed in the AST and pick up if it’s being read before setting its value. Many static analyzers let developers configure what rules to enforce and their severity.
Why Use Static Code Analysis
Static code analyzers help your development team build consistent and efficient code. They can scan code for quality, maintainability, or security issues and generate a report for the developer to review.
These scans can pick up issues in seconds that even an experienced developer might take hours to find.
Detecting and proactively patching these bugs and security issues can save companies from data loss and legal challenges caused by security vulnerabilities.
Some companies, like RR Mechatronics, also use static analyzers to help keep code compliant.
Static code analyzers can also help address technical debt, which occurs when teams implement quick solutions without fully considering how maintainable they’ll be in the future.
These quick solutions are often necessary to meet urgent business needs.
However, as technical debt accrues, the risk of unexpected bugs and breakdowns in code becomes larger.
If left unchecked, small changes to one portion of a codebase may break something seemingly unrelated.
For example, updating the code that sends an order confirmation email when a user makes a purchase on a website might break seemingly unrelated functionality like the “forgot password” email.
Static code analyzers can identify code patterns that cause technical debt and alert developers.
If alerted early enough, developers can fix the debt before merging it.
If the change is urgent, the team may merge the code and keep the analysis report as a reference when refactoring.
DATEV, one of Europe’s largest IT providers, uses static code analysis to ensure high-quality code while porting legacy systems to modern platforms.
While code analysis can catch many issues, it’s not perfect.
Code analyzers might identify false positives in code (i.e. report defects that aren’t real issues). Teams must review the results and identify and handle each false positive appropriately.
Similarly, it’s vital that developers review code for potential higher-level maintainability and code-architecture issues that analyzers might miss.
For example, an engineer can identify if a design pattern, like the Factory pattern, is being used excessively or inappropriately in a codebase.
They can also spot instances where an abstraction is inappropriate, leading to convoluted code.
When to Use Static Code Analysis
Static code analyzers will prove helpful in almost any codebase. However, choosing an analyzer, setting it up, and maintaining it in your codebase might not be worthwhile.
For example, a static analyzer might be overkill if you’re building a small utility library with one or two functions.
Code analyzers are beneficial when you’re working with a large and complex codebase.
They can enforce coding standards across different teams that might work on various portions of the codebase, ensuring the quality of changes made to the codebase remains consistent across teams.
Analyzers are also helpful when you’re working on security-critical projects.
They can highlight exploitable code and identify third-party packages with security vulnerabilities.
This helps developers proactively write secure code that minimizes the risk of data breaches or system takeovers.
Minimizing these security risks is particularly important in writing code for a heavily regulated industry like the medical industry or government.
Analyzers are also vital for mission-critical systems, where any security vulnerability might derail a company.
How to Do Static Code Analysis
Setting up static code analysis in your codebase requires some upfront investment. Afterward, the analyzer can run automatically in a developer’s IDE or a repository.
Choosing a Suitable Static Code Analyzer
There are a few things to consider when choosing a static code analyzer for your codebase.
Most importantly, make sure that the analyzer supports your programming languages.
Some analyzers support a broad range of languages, while others focus on one in particular.
Analyzers tailored to a specific language can be beneficial as they can usually detect distinct issues and enforce best practices that general analyzers might miss.
This is especially true when dealing with issues related to code formatting, which varies by language.
You should also consider the analyzer’s capabilities.
Some analyzers detect code-style issues, while others can detect security vulnerabilities and potential performance optimizations.
While comprehensive analyzers are preferred, they come at an extra cost and can require more effort to configure.
Decide what level of customization and configuration you want for analyzer rules.
Limited analyzers usually let you turn rules on or off, while more advanced analyzers let you specify the severity of different issues and even create custom rules.
Your choice of analyzer largely depends on your specific requirements.
You could opt for free or inexpensive limited analyzers, which often suffice.
However, if your team needs more control over analyzer rules, you might have to spend a bit more on an analyzer supporting that.
Finally, consider your source code provider and CI/CD pipelines.
Integration with your pipelines and source code provider is vital for incorporating static code analysis in your development workflow.
This way, the analyzer can enforce and reject any code changes that don’t meet the standards defined in the analyzer.
Some analyzers have existing integrations for these tools and platforms, which simplify integrating them into your development workflow.
Others require a bit more manual setup to get them running in your CI/CD pipelines.
Some analyzers can also run on developers’ machines and integrate directly with their IDEs.
By running the analyzer in your developers’ local development environments, they can detect and fix issues as they go, reducing the time it takes to correct them later.
Configuring the Tool
Many basic analyzers and programming language-specific analyzers can be installed on developer machines and in CI/CD pipelines and run standalone. More comprehensive analyzers might come as a hosted service or a self-hosted package you install on your server.
Many analyzers are configured with sensible defaults, meaning you can run the analyzer as soon as it’s installed.
These defaults often include enforcing standard naming conventions for a programming language and highlighting common performance pitfalls.
However, you’ll probably want to tailor these rules to your team’s coding standards.
For example, your team might have a particular naming convention for static variables that you want the analyzer to enforce.
You might also have code style preferences, like always using semicolons in languages where it’s optional or always having a trailing comma when listing objects in an array.
By configuring the analyzer to look for these issues, it’ll automatically enforce these preferences throughout the codebase.
When configuring rules, you should also decide the severity level associated with each rule.
For example, formatting code contrary to the preferred code-style rules might make it less readable.
Suppose you configure the analyzer to treat specific code-style rules as suggestions rather than errors.
In this case, engineers can format the code contrary to the rules without the analyzer rejecting the code change.
On the other hand, you should configure the analyzer to treat issues like infinite loops as high-severity.
This way, the analyzer will report an error if an engineer submits code that might cause an infinite loop.
Running the Analysis and Interpreting Results
Static code analyzers are often triggered in code repositories when code is updated. The analyzer checks the new code for defects, generates a report, and then attaches that report to the change request.


However, some analyzers can even run on the developer’s machines. These can run as standalone applications or can be integrated into different IDEs.

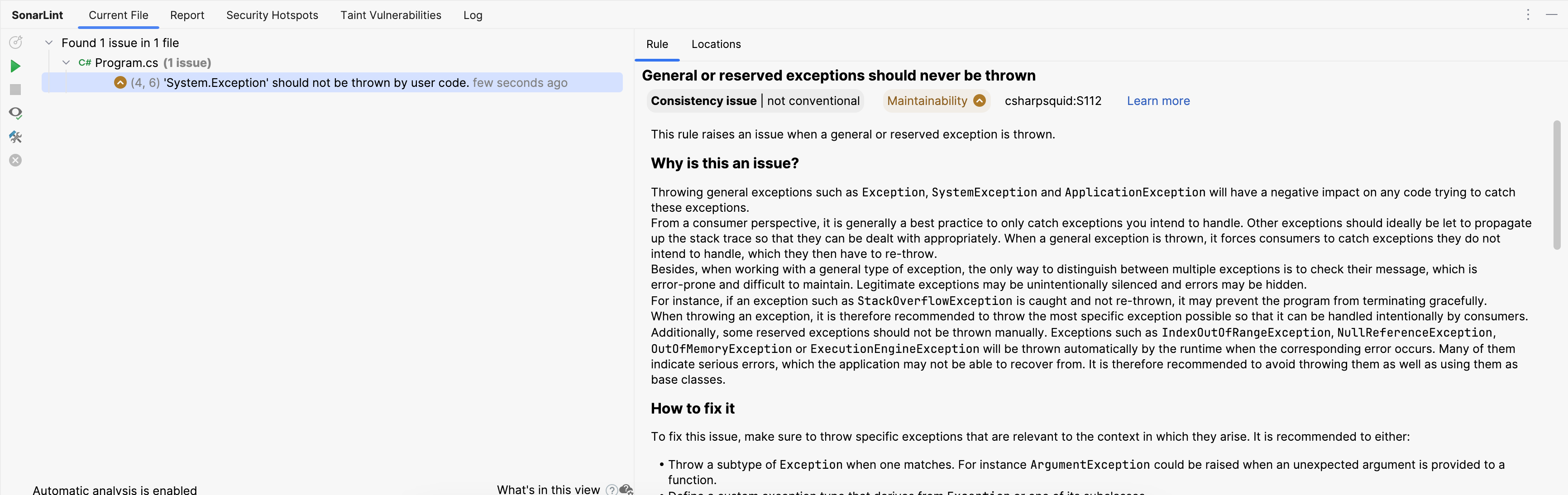
Human reviewers should look over the generated report, which lists the issues in the changed files. Many analyzers provide more details about the problem, and some can even suggest corrections to fix it.

Just because an analyzer reports an issue, that doesn’t necessarily make it a real issue.
The report might include false positives. Identifying these false positives is generally language-specific and requires some experience with the codebase and programming language. However, there are some guidelines teams can follow when identifying false positives:
- Check if the issue has been highlighted as a false positive before: If the issue has previously been identified as a false positive with sound reasoning to justify the decision, then you can probably safely ignore it.
- Look at the bigger context: Investigate the lines of code around the issue. If the issue is inside a method, look at where the function gets called to see if the scenario highlighted by the analyzer will ever happen. For example, the analyzer might think a function should be marked as
private, but the method is used somewhere in the codebase that the analyzer missed. - Look at external library documentation: If the issue is with code that deals with external libraries, then check the documentation for that library to see if the potential problem will ever occur. For example, an analyzer might complain that a variable will be
null, but the documentation for the external code says the variable will always have a value. - Test the code by running it: If you still can’t decide if an issue is a false positive, run the code with different inputs and see if the problem highlighted by the analyzer ever occurs. For example, the analyzer might suggest simplifying a method, but when you run the method, you discover log messages are no longer printed.
Once these false positives are confirmed, you should keep track of them so the team can quickly identify them in the future.
Also, if the analyzer supports it, you should configure it so it doesn’t highlight those false positives in the future.
Addressing Identified Issues and Improving Code
If the analyzer finds legitimate issues when scanning proposed code changes, you should fix them immediately.
If teams don’t follow the analyzer’s suggestions, it can defeat the point of using one.
Ignored issues will create technical debt and negatively impact the code’s readability and maintainability over time.
Fixes for the highlighted issues should ideally happen before the code is merged or released.
For example, if the analyzer found an issue in a pull request, the author of that pull request should address the problem before merging the pull request instead of merging the code as is and fixing it in another pull request.
Once the code author implements the fix, the analyzer should scan the code again to ensure the proposed fix addresses the original problem. If it does, the team can merge the code.
If there’s not enough time to follow the process above—for example, if the fix is an urgent hotfix—the team should document why they chose to ignore it.
You can also put these issues on the team’s backlog to be fixed later.
The team should set aside time to resolve these issues later to avoid accumulating too much technical debt.
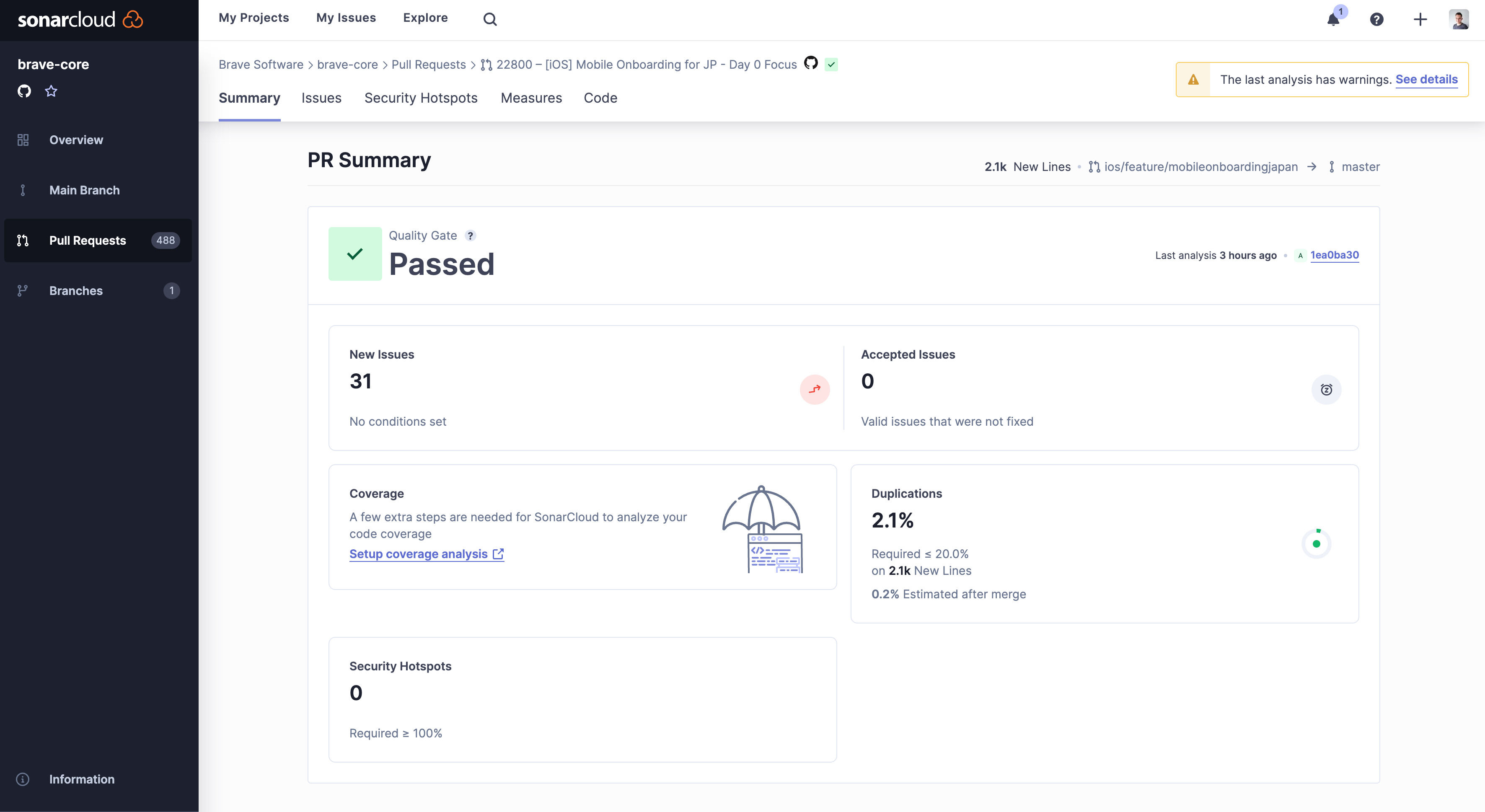
Sonar and Static Code Analysis
Your team can pick from many analyzers available in the market. Each analyzer has different features and supports one or more programming languages.
Sonar is an analyzer that supports over thirty programming languages and frameworks, making it a robust solution for organizations using multiple technologies.
Sonar has an extensive rules library tailored for each programming language.
Teams can customize these rules if necessary and create custom quality gates (ie requirements for acceptable code).
Sonar’s detailed reports offer guidance on how to resolve different defects.
Their dashboards also let teams see a big picture of their codebase’s overall quality.

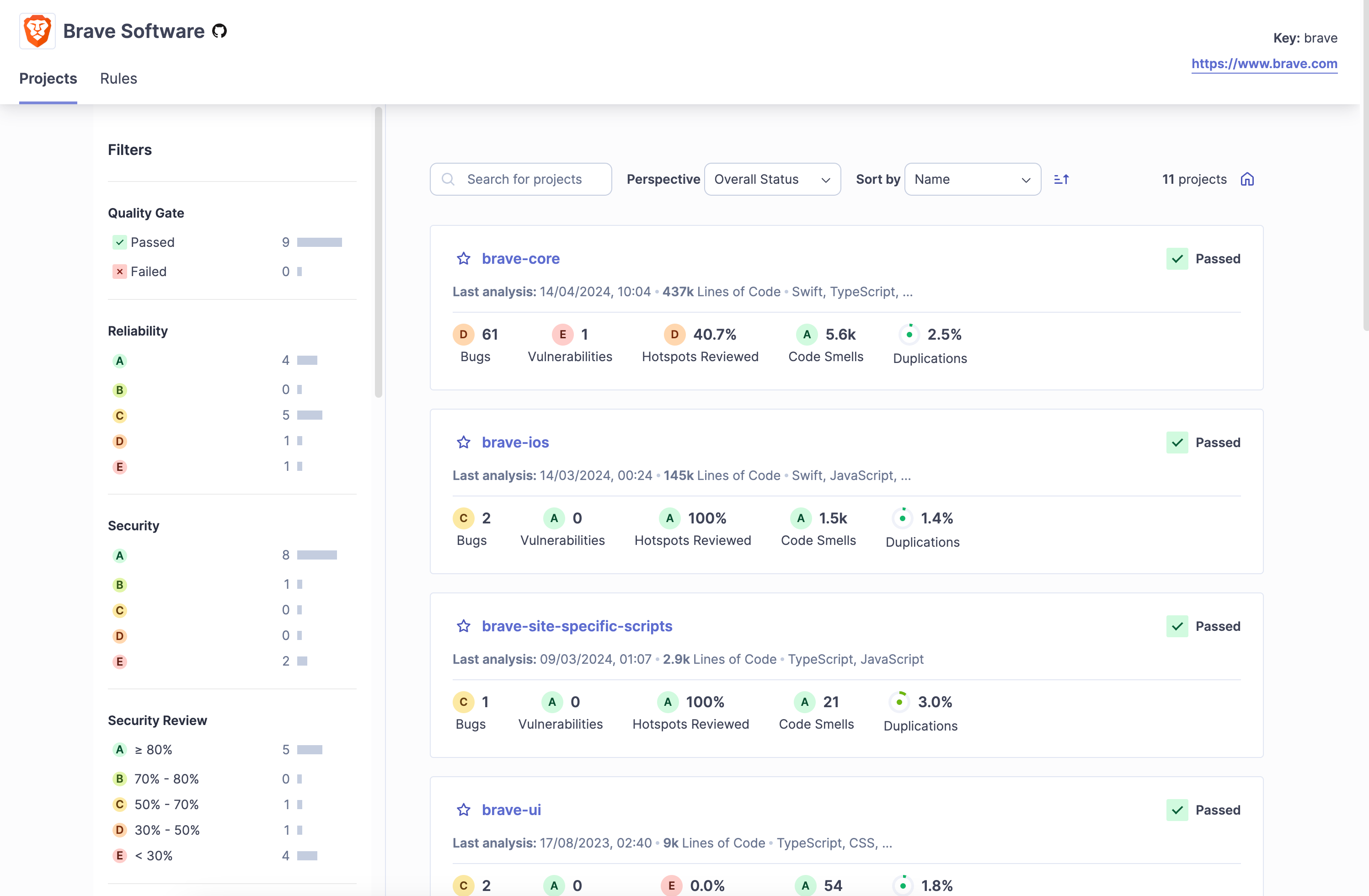
The analyzer integrates with several popular IDEs, such as IntelliJ and Visual Studio Code.
Teams can also run the analyzer in their CI/CD pipelines using integrations for GitHub, GitLab, and more.
These integrations allow you to incorporate Sonar into several of the earliest stages of the development workflow and catch issues while writing code.
This helps to avoid the delays and unnecessary effort of going back and fixing code after they’ve finished modifying it.
Conclusion
Static code analysis is a powerful tool that helps developers identify and address potential issues in their code early in the development process. It can catch bugs, security vulnerabilities, and code-style issues, saving valuable developer time and effort.
Integrating code analysis into your development workflows promotes clean, maintainable, and secure code.
Additionally, teams must diligently review the generated reports to decide which issues are false positives and which must be fixed.
A static code analyzer like Sonar is an excellent option for streamlining your development process and writing more maintainable, Code Quality.
The tool’s intuitive interface and robust feature set make it ideal for small and large organizations. View Plans and Pricing to discover how Sonar can help your team.
This guide was written by Ivan Kahl as part of the developer guide for Static Code Analysis.
- June 14, 2024